Random Numbers:
- Total Strands: 98, 4 each Red/Blue/Green/White, 2 Meteor
- LEDs: 9,888
- Controllers: 1x Pi Zero, 1x RS-485 Repeater, 14 RS-485 Controllers
Coding, Beer, whatever else

Random Numbers:
Looks like the password phishers are finally starting to learn proper grammar and piece together something kinda convincing. Here’s a breakdown on one that I had reported to me over the UMD holiday break. It’s notable for a few reasons:
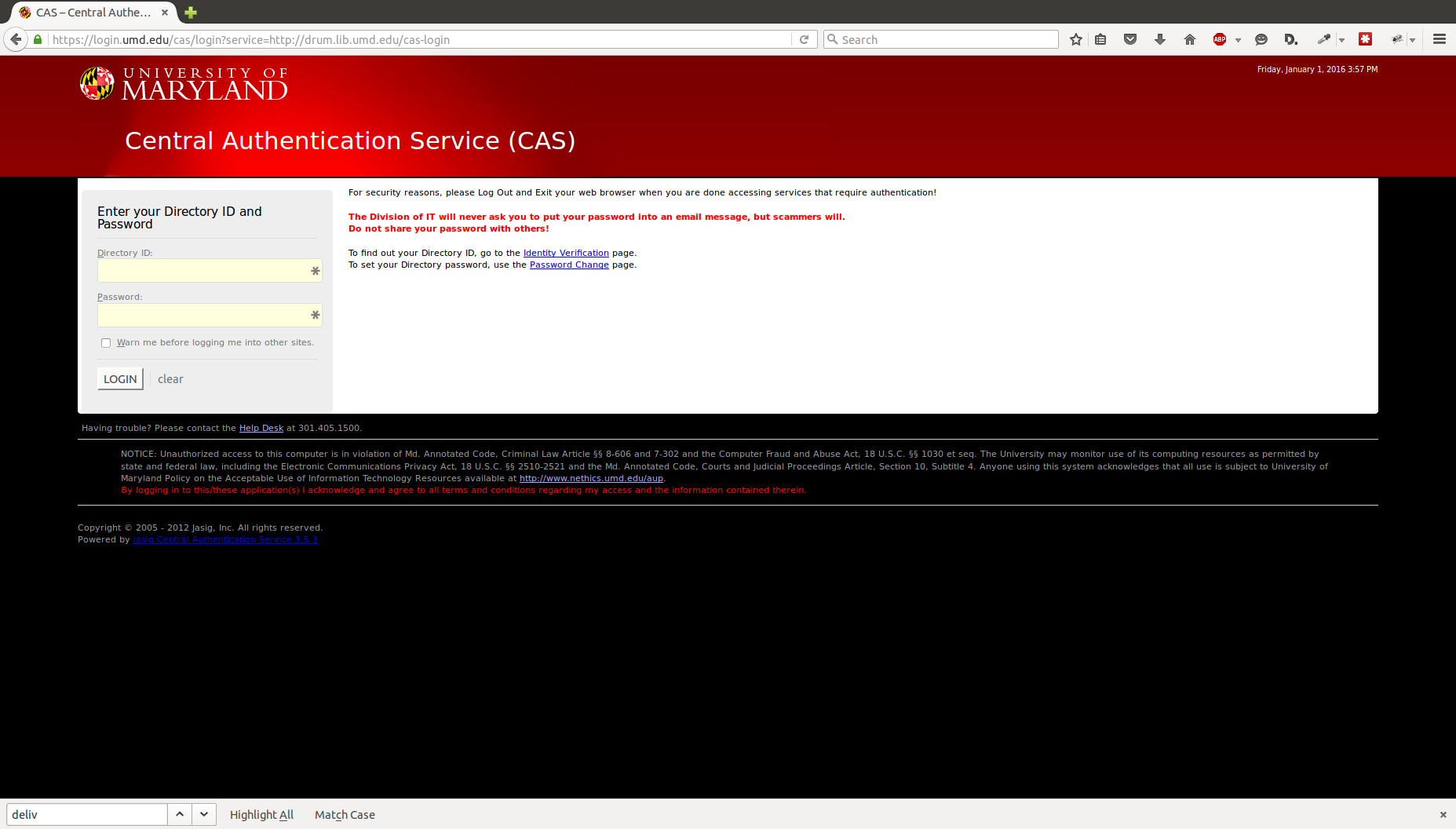
Here’s the actual email received from these guys. A few things they got correct:
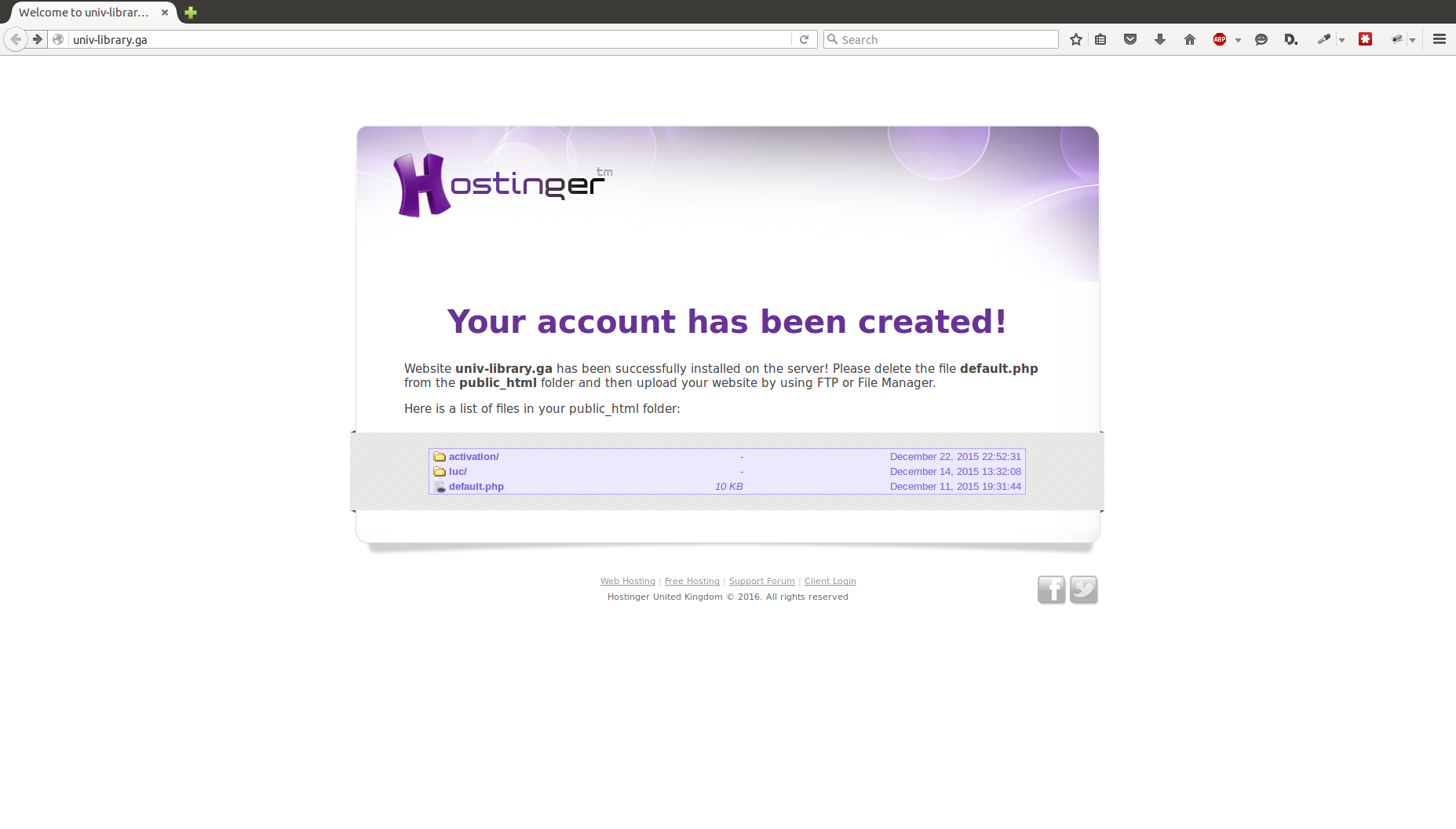
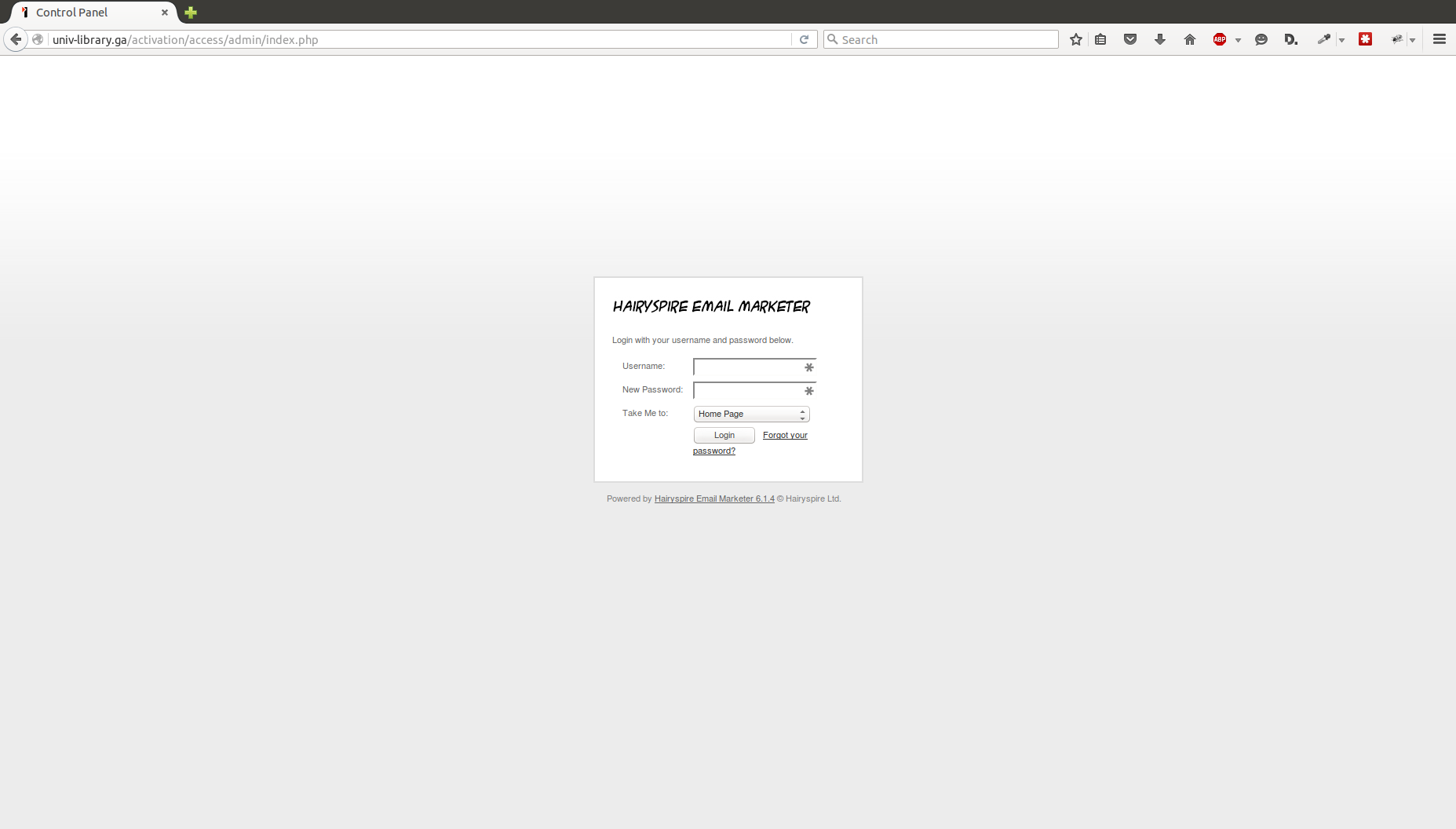
The login they created for this account is a pretty convincing copy of UMD’s actual CAS login page. The top/forged one uses graphics from UMD. Looking at the source, the login form has been modified to send the response to save.php.
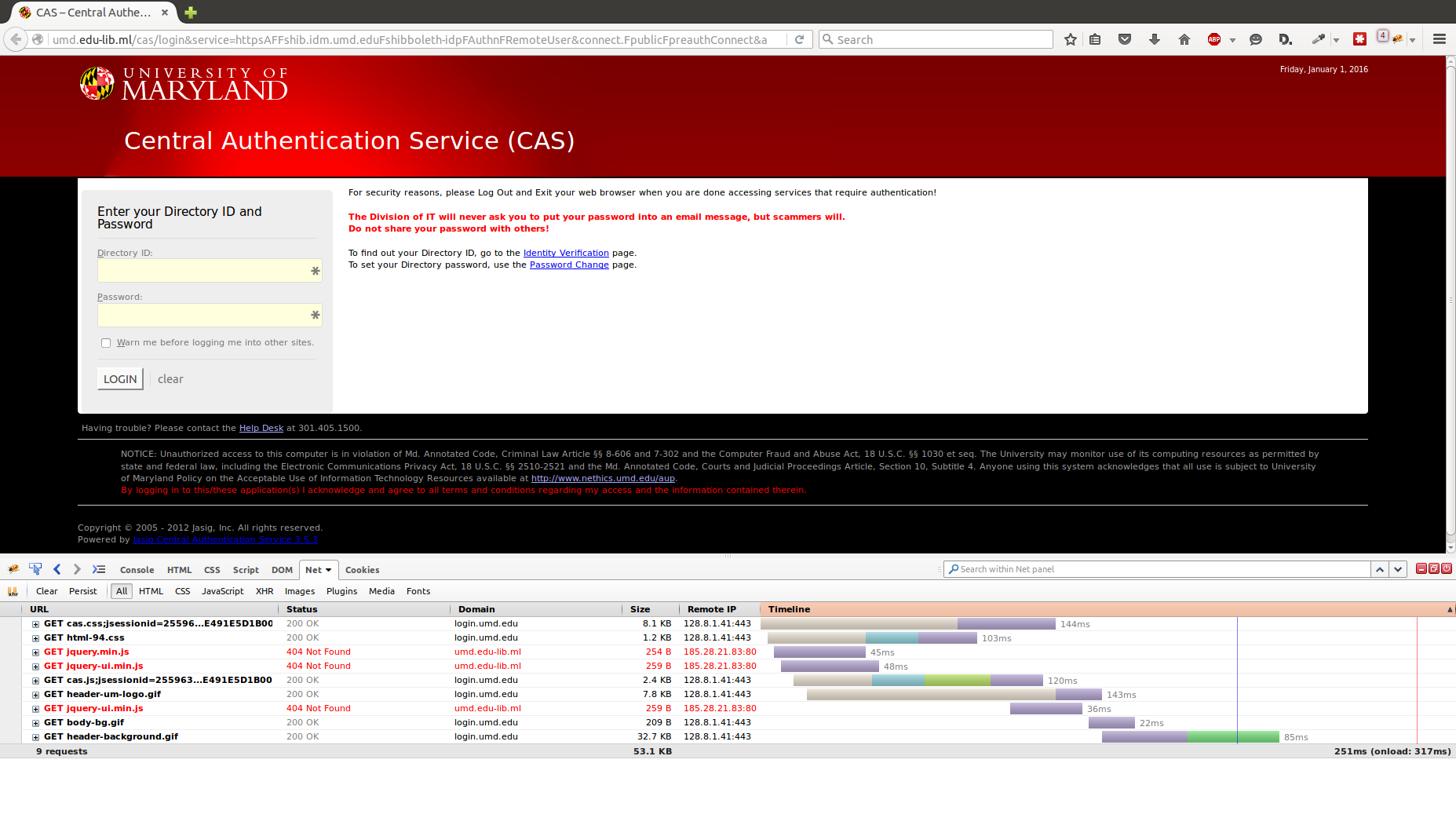
If you go to the root domain, edu-lib.ml, there are a half a dozen other universities listed with what I’m assuming are forged copies of their login pages. Entering any username and password into the password field results in a message saying your services have been activated and a link back to UMD’s library main page.
Overall, I’d have to give this one a B+ for the realness factor. Sadly, it probably picked up quite a few accounts given timing, etc.
Quick hack to have a bounded slider in Konva
(Hardware updated 10/2016)
Our standard Adobe Connect, Skype and Lync compatible conference configuration is designed to provide skype-quality audio and video in and out of a conference room. While a more advanced, high end system would be nice, the types of hardware/software that our ever changing endpoints make that prohibitively expensive. Instead, we rely on most current software’s ability to provide decent full duplex built-in echo cancellation. Flash, Skype and Lync all do this pretty well, we’ve had some difficulty with Webex and early releases of Google Hangouts.
Our goal is to provide complete audio coverage for any participant sitting at a table in our conference room. As our meetings tend to be mostly round-table style discussion a rule of one microphone for every two people allows us to pick up normal conversation-level speech.
Our requirements are that we allow remote participants virtually join meeting in conference rooms ranging in size from 8 through 24 people. Realistically for groups larger than 16-18 the logistics of ensuring that remote participants are fully included in a meeting starts to break down. Distance to TV, etc start to have an detrimental effect on the ability of remote participants to be heavily engaged in a meeting.
Video:
Audio:
Television/Stand:
Misc Parts:
Total Cost (no PC): ~$3,000 $3,700 (8 person) – $5,150 $5,850(24 person)
Here’s a good tutorial on using jax-rs to return smartclient compatible data sources.